Raft Part I - Leader Election
Resource:
I just spent four days completing the first checkpoint for the Raft consensus algorithm, so here’s a summary. Raft will be divided into two parts. In the first part, I'll implement leader election in Go and explain the core test design. It’s quite fitting to work on a democratic election project right as the U.S. 2024 election approaches, haha.
Core Ideas
First, we need three states for the server: leader, follower, and candidate. In the article:
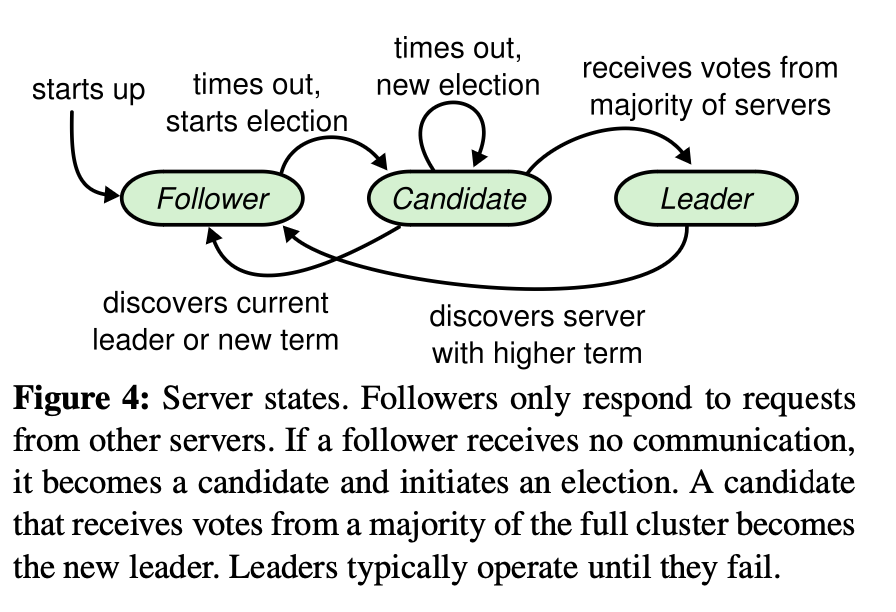
As part of program design, I’ve made this section more concrete by defining it in terms of several channels within the run() function, which handle signals as follows:
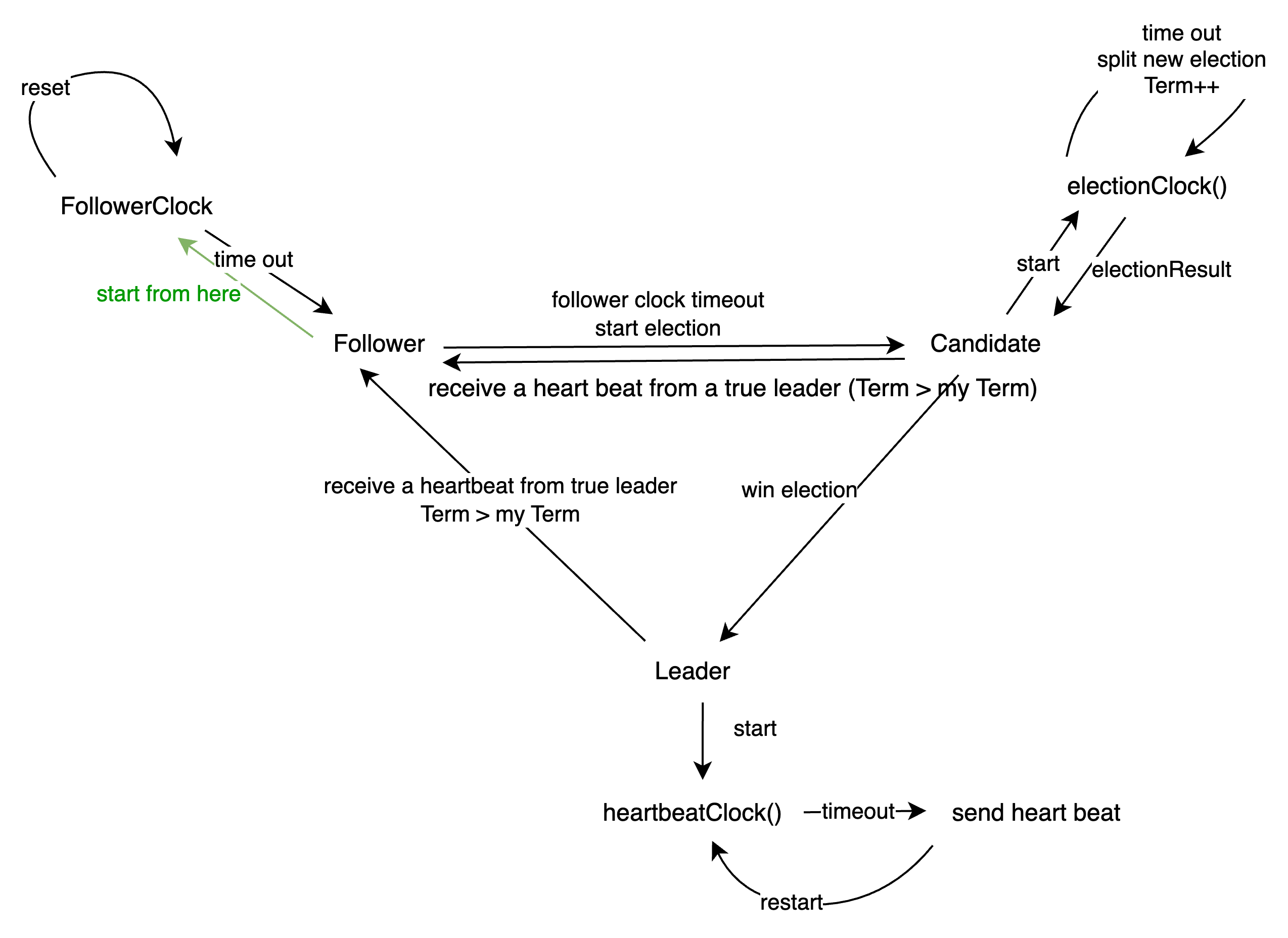
Implementation Details
run() function
The run() function is launched by a goroutine when initializing a server, and it acts as the central handler for various inputs.
- If it receives input from
←rf.endRunCh, this indicates that the goroutine should end, so it terminates this function.
- If it receives input from
←rf.startLeaderCh, it means this server has successfully become the new leader through the election, triggering two actions:- Acquire a lock, change the role to leader, then release the lock.
- Start the
go heartbeat()function.
- If it receives a heartbeat from the leader server (
←rf.heartbeatIn), we handle it as follows:- If this server is a follower, reset the follower clock with
rf.resetFollowerClock <- struct{}{}to extend its “lifetime” with a new random timeout.
- If this server is a candidate and its
Termis less than or equal to theTermin the received heartbeat, it indicates that a leader has already been elected for thisTerm, or that this server is behind by severalTermversions:- First, stop the election.
- Then downgrade to follower status.
- Update to the current
Term.
- If this server is the leader and the heartbeat’s
Termis greater than its ownTerm, this indicates it is an outdated leader and will be replaced:- First, stop the heartbeat function.
- Then downgrade to follower status.
- Update to the current
Term.
- If this server is a follower, reset the follower clock with
followerClock() function
This function manages the timer for a Raft node in the follower state, detecting the leader’s heartbeats. If no heartbeat is received within a specified timeout, the node transitions to the candidate state and initiates a new election process.
- Timer Initialization: The function initializes a timer at the beginning and ensures it stops when the function exits to free resources.
- Timeout Setting: In each loop, the timer is reset to a random timeout (between 1000 and 1500 milliseconds). This randomness helps reduce the chances of multiple nodes initiating an election simultaneously.
- closeFollowerClock: If this channel receives a signal, the function will exit.
- Timer Timeout: If the timer times out, meaning no leader heartbeat was received within the specified period, the node initiates a new election through the
startNewElectionChchannel.
- resetFollowerClock: If this channel receives a signal, the timer resets, typically indicating the node received a leader’s heartbeat, thus continuing as a follower.
election() function
After starting the election() function:
- Set identity to
Candidate.
- Increment
currentTermto update the term.
- Set
voteFor = meto vote for itself.
Then launch three functions:
go rf.electionClock(stopElectionClockCh)
go rf.elecParallelSend(stopElecParallelSend)
go rf.electionRecv(stopElectionRecv)
Afterward, handle signals:
- If
<-rf.electionTimeoutCh, it means the server did not receive the majority of votes during the election, and it is uncertain if a leader was elected, so it starts a new election round:rf.startNewElectionCh <- struct{}{}
- If
<-rf.closeElectionCh, it indicates, via therun()function’s signal relay, that a new leader has been elected, so this election should end.- The function uses
deferto close channels and perform cleanup:defer func() { close(stopElectionClockCh) close(stopElecParallelSend) close(stopElectionRecv) // drain the voteIn channel for len(rf.voteIn) > 0 { <-rf.voteIn } // fmt.Printf("\\033[33m[Term:%d](%d) election done\\033[0m\\n", rf.state.currentTerm, rf.me) }()
- The function uses
- If it receives the election result
electionResult := <-rf.voteCollectCh:- If successful:
rf.startLeaderCh <- struct{}{}to start leader mode.
- If
electionResult == splitVote, start a new electionrf.startNewElectionCh <- struct{}{}.
- If successful:
elecParallelSend() and electionRecv() functions
When sending voteRequest, the article mentions it should be sent in parallel. Here we ensure concurrency, so the logic is correct. Use:
go rf.sendRequestVote(i, &RequestVoteArgs{
Term: curTerm,
CandidateId: rf.me,
LastLogIndex: logLen - 1,
LastLogTerm: curTerm,
}, reply)
Send the RPC, and remember to lock when accessing the state variable; otherwise, it might conflict with other operations modifying state.
Upon receiving the RPC response, immediately return, so we set up a buffered channel to collect each voter’s result:
if ok && reply.VoteGranted {rf.voteIn <- true}
Then, collect the votes in the electionRecv() function with vote := <-rf.voteIn.
electionClock() function
The electionClock function is simpler than followerClock, needing only to check if the countdown finishes first or if an external signal ends the goroutine first.
RequestVote()
This is critical!!! As the RPC handler function, its correct implementation determines whether the election proceeds smoothly. Lock and unlock the entire function to ensure state consistency before and after voting. Three scenarios apply:
args.Term > rf.state.currentTerm- Vote:
reply.VoteGranted = true
- Update
Term:rf.state.currentTerm = args.Term
- Record the vote for this candidate:
rf.state.votedFor = args.CandidateId
- Then, consider the following:
- If this server is a
Candidate:- Change to
Followerand startrf.followerClock().
- Stop the election
rf.closeElectionCh <- struct{}{}
- Change to
- If this server is a
Leader:- Change to
Followerand startrf.followerClock().
- Stop the heartbeat
rf.closeHeartbeatClock <- struct{}{}
- Change to
- If this server is a
Follower:- Reset the timer
rf.resetFollowerClock <- struct{}{}
- Reset the timer
- If this server is a
- Vote:
args.Term == rf.state.currentTerm- Do not vote. Why? Even as a follower? Yes, because if they were the leader for this term, they should send a heartbeat rather than a vote request. They’re in the same term as you but still running an election? To be valid, they should be at least one term ahead!
args.Term < rf.state.currentTerm- Refuse the vote and inform them of the latest
Term:reply.Term = rf.state.currentTerm.
- Refuse the vote and inform them of the latest
heartbeat(), sendHeartbeat() functions
Straightforward, each countdown resets and initiates a new countdown, starting a goroutine go sendHeartbeat().
sendHeartbeat() is simple, issuing RPC to all servers with go sendAppendEntries().
AppendEntries() function
Also crucial!!! Similar to RequestVote, it has three main cases. Lock at the beginning and unlock at the end.
args.Term < rf.state.currentTerm- Failed heartbeat:
reply.Success = false
- Failed heartbeat:
args.Term == rf.state.currentTerm- If a follower:
reply.Success = true
- Otherwise:
reply.Success = false
- If a follower:
args.Term > rf.state.currentTermreply.Success = true
Send the heartbeat Term to run for further processing: rf.heartbeatIn <- args.Term.
Test Design
TestInitialElection2A
- Objective: Verify if the system can correctly elect a leader at initialization.
- Procedure: Create a cluster of three servers and check if a leader is elected.
TestReElection2A
- Objective: Check if the system can elect a new leader when the current leader disconnects.
- Procedure: Disconnect the current leader in a three-server cluster, then check if a new leader is elected.
TestReElectionHidden2A
- Objective: Test if the system can re-elect a leader after a network failure.
- Procedure: In a five-server cluster, disconnect the current leader and elect a new leader, simulate a network partition by disconnecting several nodes, check for no leader condition, then restore connections and check if a new leader is elected.
TestSmallPartitionConsensusHidden2A
- Objective: Test if the system can elect a new leader in the majority partition while maintaining the old leader in the small partition under network partition conditions.
- Procedure: In a five-server cluster, create a small partition with the leader and one follower, and a large partition with the majority of followers. Check if a new leader is elected in the large partition and verify the old leader remains leader in the small partition.
TestLeaderConsistencyHidden2A
- Objective: Verify if the system maintains leader consistency after a re-election.
- Procedure: In a three-server cluster, disconnect the current leader and elect a new leader, reconnect the old leader, disconnect the new leader and another node, and check if a new leader can be elected.